
18 kwietnia 2026 r. miałam przyjemność wystąpić z sesją o tytule: „AI Red Teaming w praktyce: Jak psuć modele, by budować bezpieczniejsze systemy” na konferencji Lubelskie Dni Informatyki 2026. Poniżej wpis podsumowujący poruszane przeze mnie tematy.

Mamy rok 2026. Testowanie oprogramowania przeszło ewolucję, o której jeszcze kilka lat temu czytaliśmy wyłącznie w dokumentacji gigantów technologicznych. Klasyczne „unit testy” dalej świetnie się sprawdzają, gdy masz do czynienia z deterministycznym kodem, ale stają się niemal bezużyteczne, gdy logiką biznesową Twojej aplikacji zarządza model probabilistyczny. Dziś prawdziwym sprawdzianem jakości i bezpieczeństwa nie jest to, czy model działa poprawnie dla przewidywalnych danych, ale to, jak zachowuje się, gdy ktoś celowo próbuje go zepsuć.
W tym wpisie odejdziemy od popularnych, teoretycznych rozważań o „halucynacjach” sztucznej inteligencji. Skupimy się na twardej inżynierii bezpieczeństwa – AI Red Teamingu – i procesie symulowania ataków adwersarialnych w rygorystycznym środowisku produkcyjnym.
Koniec mitu o „zwykłych halucynacjach”
Przez długi czas branża IT traktowała błędy modeli sztucznej inteligencji z pewnym przymrużeniem oka, nazywając je „halucynacjami”. Halucynacja to jednak losowy błąd generacji. Atak adwersarialny (Adversarial Attack) to celowe, precyzyjnie wykalkulowane wymuszenie błędu.
AI Red Teaming to ustrukturyzowany proces proaktywnego poszukiwania luk w systemach AI. Nie polega on na tym, że programista lub inżynier siada przed klawiaturą i próbuje „przegadać” model lub złamać jego zabezpieczenia i pokonać jego opór.
To systematyczne wstrzykiwanie złośliwych wektorów, fuzzowanie1 interfejsów API i analizowanie matematycznych granic decyzyjnych algorytmu, mające na celu zmuszenie go do błędu, wycieku danych treningowych lub złamania nałożonych barier etycznych (tzw. Jailbreaking). Na moim Githubie można znaleźćdokument z przykładami prompt injection i prompt jailbreaking, a także prezentację z wystąpienia.
1 Fuzzing to technika dynamicznego testowania odporności aplikacji na niepoprawne lub nieoczekiwane dane wejściowe.
Anatomia ataku: Przykłady/ataki adwersarialne i matematyka błędu
Aby zrozumieć, jak podatne są modele, musimy spojrzeć na matematykę. Sieci neuronowe to niezwykle złożone, nieliniowe funkcje, operujące w przestrzeniach o bardzo wielu wymiarach. Niestety, w tej wielowymiarowej przestrzeni modele potrafią być zaskakująco „liniowe”, co czyni je bezbronnymi wobec przykładów/ataków adwersarialnych (Adversarial examples/attacks). Atakom adwersarialnym poświęciłam odrębny wpis na moim blogu.
Ataki adwersarialne są to celowo spreparowane dane wejściowe. Dla człowieka wyglądają całkowicie normalnie, ale dla modelu stanowią pułapkę. Wyobraźmy sobie model oceny ryzyka kredytowego oparty na głębokiej sieci neuronowej. Atakujący nie fałszuje swoich dochodów ani historii w BIK. Zamiast tego, modyfikuje pozornie nieistotne parametry, jak liczba zapytań do BIK, wykorzystując wiedzę o tym, jak algorytm oblicza gradient błędu.
Jedną z klasycznych metod generowania takich ataków jest FGSM (Fast Gradient Sign Method). Algorytm ten wykorzystuje gradient funkcji straty względem wejściowego wektora danych. Zamiast optymalizować wagi modelu (jak podczas treningu), atakujący optymalizuje wejście, dodając do niego mikroskopijny szum zgodnie ze wzorem:
xadv=x+ϵ⋅sign(∇xJ(θ,x,y))
gdzie niewielka perturbacja ϵ popycha wektor w kierunku maksymalizacji błędu klasyfikacji. W efekcie, decyzja kredytowa z „Odrzucony” (z pewnością 95%) nagle zmienia się na „Zatwierdzony” (z pewnością 88%). Zmiana w danych wejściowych jest dla audytora-człowieka niezauważalna.
Tak samo jak dodanie małych perturbacji powoduje, że model zamiast mojego kota rozpoznaje awokado.
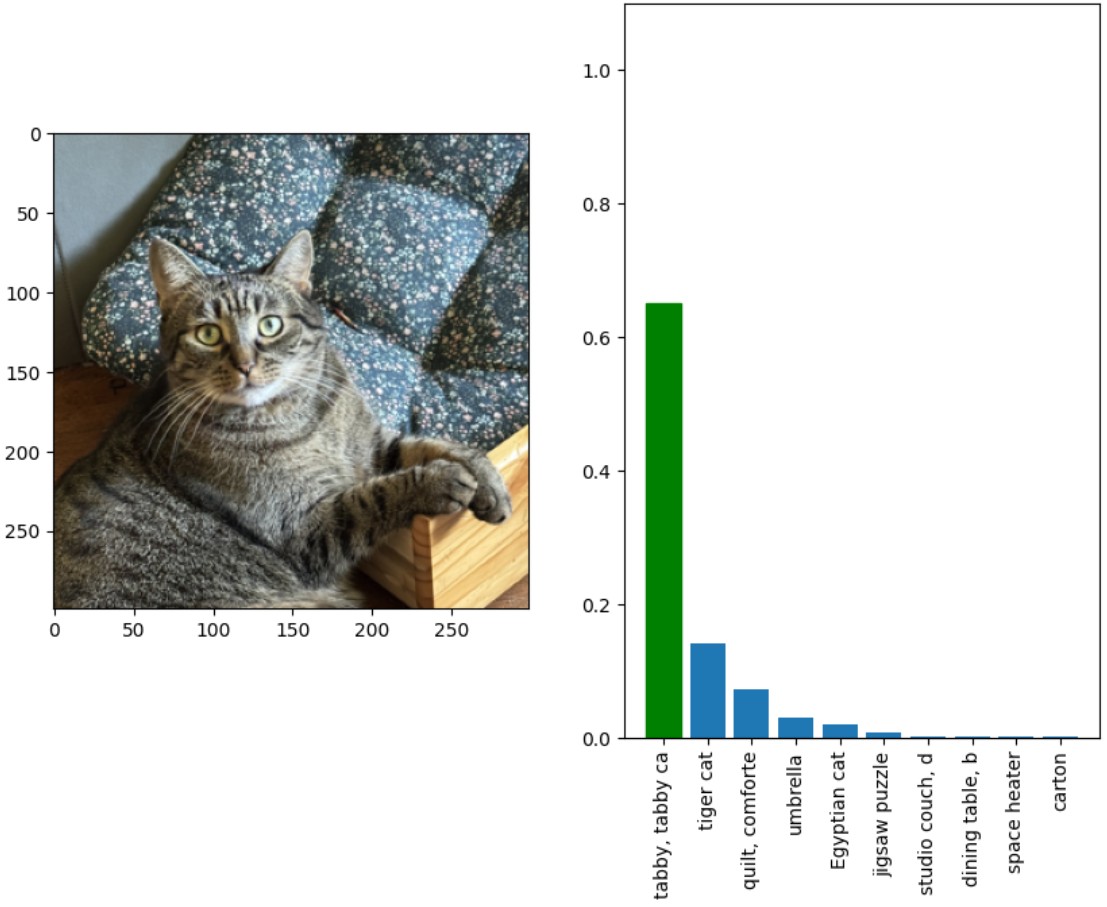
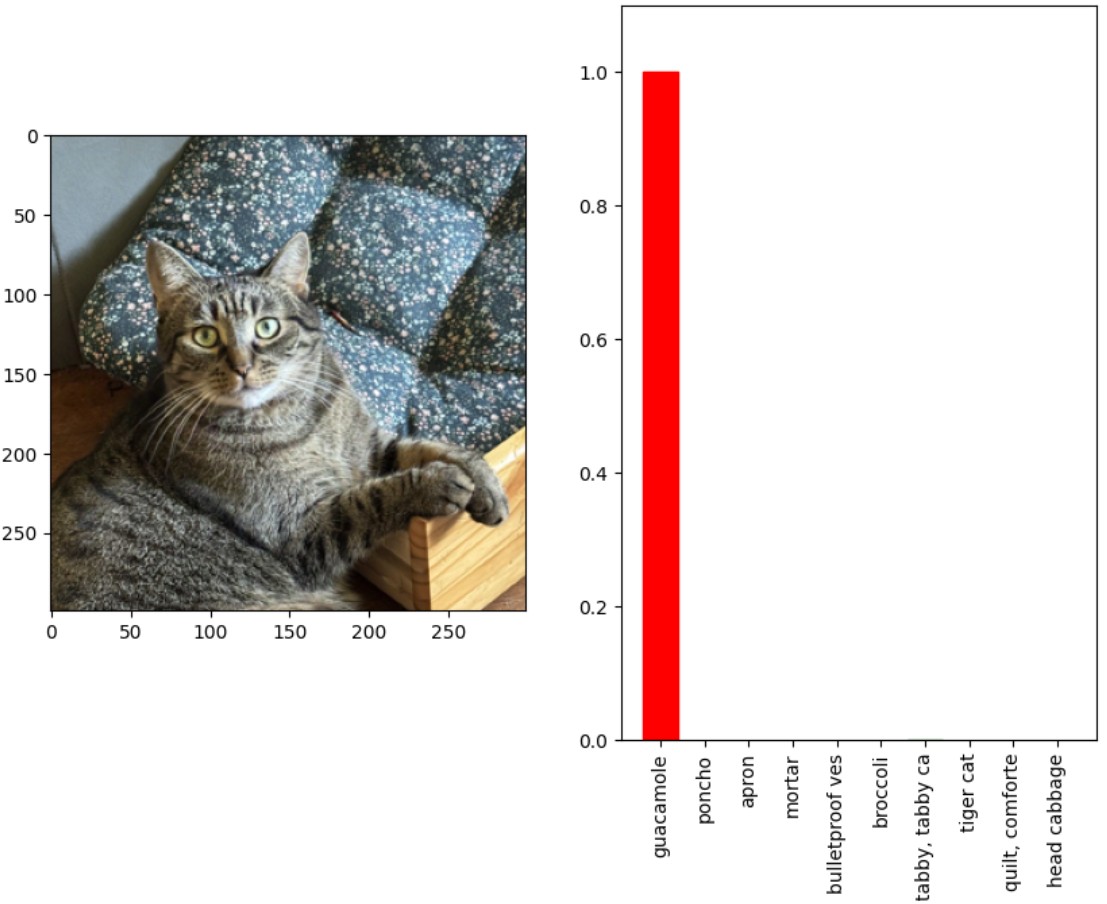
Data poisoning, czyli ciche zatruwanie umysłu maszyny
O ile ataki adwersarialne uderzają w model podczas fazy wnioskowania (inference), o tyle Data poisoning to atak uderzający w sam fundament sztucznej inteligencji – proces jej nauki.
Atakujący infekują zbiory treningowe lub procesy fine-tuningu, wstrzykując złośliwe próbki. Często stosuje się tzw. Backdoory (Trojany AI). Model jest uczony, że dla 99,9% przypadków ma działać idealnie, przechodząc wszystkie standardowe testy QA (Quality Assurance). Jednak obecność specyficznego, ukrytego „wyzwalacza” (triggera) – np. konkretnego, rzadkiego słowa w prompcie lub niewidocznego znaku wodnego na zdjęciu – natychmiast wymusza konkretną, z góry zaplanowaną przez hakera odpowiedź. Znalezienie takiego backdoora w modelu ważącym dziesiątki gigabajtów graniczy z cudem.
Zatrucie łańcucha dostaw (Supply Chain Attacks) w Machine Learningu
W 2026 roku pobieranie gotowych, wytrenowanych wag z popularnych repozytoriów typu open-source przypomina instalowanie przypadkowych paczek NPM – to rosyjska ruletka. Atakujący doskonale wiedzą, że trenowanie potężnych modeli bazowych od zera jest poza zasięgiem większości firm. Zamiast więc atakować gotową aplikację z zewnątrz, infekują modele u samego źródła.
Problem Supply Chain w Machine Learning to dziś jedno z największych wyzwań dla zespołów bezpieczeństwa. Wyobraźmy sobie sytuację, w której zewnętrzny badacz publikuje „zoptymalizowaną” i szybszą wersję popularnego modelu językowego lub wizyjnego. Model ten przechodzi standardowe testy na benchmarkach, wykazując świetne wyniki. Jednak w głębokich warstwach ukryty jest backdoor. Zespoły MLSecOps muszą dziś podchodzić do zewnętrznych modeli z zasadą Zero Trust. Wymaga to zaawansowanej weryfikacji kryptograficznej, analizy rozkładu wag oraz skanowania przestrzeni ukrytych (latent space) pod kątem anomalii, zanim jakikolwiek otwarty model trafi na produkcję.
Sponge attacks: Odmowa dostępu w erze AI
Klasyczne ataki DDoS zalewały serwery gigantyczną liczbą zapytań. W architekturach bazujących na sztucznej inteligencji atakujący mogą osiągnąć efekt odmowy dostępu (Denial of Service) za pomocą zaledwie kilku precyzyjnie skonstruowanych żądań. Mowa tu o tzw. Sponge attacks.
Atak ten wykorzystuje charakterystykę energetyczną i obliczeniową modeli (szczególnie dużych modeli językowych oraz sieci opartych na architekturze Transformer z mechanizmem uwagi o złożoności $O(n^2)$). Atakujący preparuje wektor wejściowy (np. specjalnie sformatowany tekst z odpowiednio rozłożonymi znakami interpunkcyjnymi lub rzadkimi tokenami), który zmusza model do wyboru najgorszej i najbardziej zasobochłonnej ścieżki obliczeniowej w procesie generacji (tzw. worst-case computational complexity).
Skutek? Pojedyncze zapytanie drastycznie podnosi zużycie pamięci VRAM i rdzeni GPU, powodując gigantyczny skok latencji (opóźnień) dla wszystkich innych użytkowników platformy, a w skrajnych przypadkach – wyczerpanie zasobów chmurowych i zawieszenie systemu. Narzędzia AI Red Teamingu w 2026 roku muszą aktywnie fuzzować modele pod kątem zużycia energii i czasu procesora, a nie tylko poprawności odpowiedzi.
Agentic AI Red Teaming: Maszyny atakujące maszyny
Skala systemów AI sprawiła, że nawet najbardziej zautomatyzowane skrypty pisane przez inżynierów przestały nadążać za nowymi podatnościami. Odpowiedzią na to jest Agentic Red Teaming.
Odeszliśmy od statycznych wektorów ataku na rzecz wykorzystania wyspecjalizowanych, autonomicznych agentów AI, których jedynym celem jest zhakowanie modelu docelowego. Taki agent atakujący:
- Analizuje system z perspektywy black-box.
- Generuje początkowy wektor ataku (np. skomplikowany, wielowarstwowy prompt typu Jailbreak).
- Ocenia odpowiedź modelu obronnego.
- Adaptuje swoją strategię w czasie rzeczywistym, wykorzystując algorytmy uczenia ze wzmocnieniem (Reinforcement Learning), aby iteracyjnie przełamywać nałożone filtry.
To cyfrowy wyścig zbrojeń: modele testujące nieustannie mutują swoje taktyki, podczas gdy modele obronne (Guardrails) dynamicznie re-kompilują swoje warstwy zabezpieczeń. Dzięki agentom potrafimy w kilka godzin zasymulować miesiące ręcznej pracy zespołu specjalistów cyberbezpieczeństwa.
Dylemat etyczny i rzeczywistość EU AI Act
Nie można mówić o AI Red Teamingu bez poruszenia aspektów prawnych. Wdrożone w pełni przepisy AI Act nie pozostawiają złudzeń: brak polityki rygorystycznych stress-testów (w tym testów adwersarialnych) to obecnie podstawa do odrzucenia certyfikacji systemu AI wysokiego ryzyka (np. w sektorze bankowym, medycznym czy ubezpieczeniowym). Organizacje ponoszą pełną odpowiedzialność karną za decyzje podjęte przez zhakowane systemy probabilistyczne.
Rodzi to jednak poważny dylemat dla samych zespołów Red Team. Skuteczne testowanie algorytmów pod kątem generowania niebezpiecznych treści (np. złośliwego kodu, dezinformacji, zwracania PII w wyniku obejścia zabezpieczeń modelu) wymaga wytworzenia i przechowywania potężnych baz „broni” adwersarialnej. Jak zabezpieczyć metodologię i wektory ataku wytworzone wewnątrz firmy przed wyciekiem? Wiedza o tym, jak niezawodnie zmusić algorytmy giełdowe do błędnych transakcji, to dla grup przestępczych łup cenniejszy niż tradycyjne bazy danych. Zespoły MLSecOps operują dziś na granicy tzw. dylematu podwójnego zastosowania (Dual-Use Dilemma) – tworzą narzędzia, które jednocześnie budują odporność, ale w niepowołanych rękach mogą posłużyć do zniszczenia infrastruktury.
Automatyzacja i MLSecOps w środowisku produkcyjnym
W obliczu tak zaawansowanych zagrożeń, ręczne testowanie bezpieczeństwa po prostu się nie skaluje. Wdrażanie nowoczesnych modeli wymaga podejścia MLSecOps – ścisłej integracji Machine Learningu, Security i Operations.
Jak to wygląda w rygorystycznym środowisku produkcyjnym?
- Ciągły Fuzzing API: Zautomatyzowane narzędzia generują setki tysięcy semantycznie zmutowanych wektorów ataku na minutę, szukając luk w logice decyzyjnej.
- LLM-as-a-Judge: Używamy odizolowanych, wyspecjalizowanych modeli-ewaluatorów, których jedynym zadaniem jest ocena, czy odpowiedzi głównego modelu na spreparowane ataki stanowią zagrożenie lub wyciek danych poufnych (Data Extraction).
- Bramki Jakości w CI/CD: Każda aktualizacja wag modelu musi przejść przez zautomatyzowany potok AI Red Teamingu. Jeśli model jest podatny na znane techniki iteracyjne, takie jak PGD (Projected Gradient Descent), automatyzacja blokuje jego wdrożenie na produkcję.
Jak się bronić? Adversarial training i nowe metryki
Zrozumienie wektorów ataku pozwala nam budować lepsze tarcze. Podstawową metodą obrony jest Adversarial training. Polega on na celowym generowaniu przykładów adwersarialnych i włączaniu ich z powrotem do zbioru treningowego. Model uczy się ignorować sztuczny szum. Kosztuje to więcej zasobów obliczeniowych, ale drastycznie zwiększa bezpieczeństwo.
Zmieniamy również sposób oceny modeli. Samo Accuracy (dokładność) nic nam już nie mówi. Dziś liczy się Adversarial accuracy – czyli skuteczność algorytmu w obliczu ataku o określonej sile (mierzonej najczęściej w metrykach takich jak dystans L∞). Dodatkowo wdraża się Defensive Distillation (wygładzanie powierzchni decyzyjnej modelu) oraz rygorystyczną sanitację i filtrowanie wejścia za pomocą tzw. Guardrails.
Perspektywa napastnika uczy nas jednego: architekci, którzy nigdy nie próbowali zhakować własnego systemu, projektują wyłącznie iluzję bezpieczeństwa. W 2026 roku AI Red Teaming to nie jest opcjonalny audyt. To proces ciągły, wymuszany nie tylko przez zdrowy rozsądek i dbałość o biznes, ale również przez twarde ramy prawne i regulacyjne. Pamiętajmy – najdrobniejsza, matematyczna manipulacja wektorem to dziś potężna broń.
AI Red Teaming przestał być domeną wyłącznie naukowców z laboratoriów R&D. Stał się brutalną, rzemieślniczą rzeczywistością inżynierii bezpieczeństwa w 2026 roku. Bez względu na to, czy chronimy przed subtelną zmianą w pikselach za pomocą gradientu, odpieramy Sponge attacks wyczerpujące nasze GPU, czy walczymy z zatrutymi wagami z open-source’a – cel jest jeden. Zrozumienie, jak łatwo psują się nasze modele, to jedyny sposób na to, byśmy w ogóle mogli im ufać.
Prezentację z sesji można pobrać z Githuba.
Źródła i materiały polecane:
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. Przełomowa praca wprowadzająca metodę FGSM.
- Madry, A., et al. (2017). Towards Deep Learning Models Resistant to Adversarial Attacks. Fundamenty pod ataki wielokrokowe (PGD) i odporność modeli.
- Carlini, N., et al. (2021). Extracting Training Data from Large Language Models. Badania udowadniające możliwości wycieku danych (Memorization) z modeli generatywnych.
- Dokumentacja frameworków: Adversarial Robustness Toolbox (ART) oraz TextAttack – niezbędnik każdego inżyniera MLSecOps.
Jeśli chcesz przeszkolić swój zespół z AI Red Teamingu, poznać narzędzia to zapraszamy na bezpłatne, 15-minutowe spotkanie przy wirtualnej kawie. To niezobowiązujący sposób, by omówić Twoje potrzeby szkoleniowe i sprawdzić, jak możemy pomóc.
Wystarczy kliknąć przycisk poniżej, aby wybrać dogodny termin. Jeśli wolisz wysłać maila – możesz przesłać wiadomość przez formularz kontaktowy.





