
Jeszcze dekadę temu rozmowa z komputerem przypominała uderzanie głową o ścianę. Maszyny rozumiały tylko sztywne komendy, a każde odstępstwo od składni kończyło się błędem. Dziś sytuacja wygląda zupełnie inaczej. Żyjemy w czasach, w której sztuczna inteligencja nie tylko rozumie nasze pytania, ale potrafi pisać wiersze, tworzyć kod programistyczny, tłumaczyć zawiłe teksty prawne na język potoczny, a nawet zdawać egzaminy lekarskie.
Sercem tej rewolucji są LLM (Large Language Models), czyli Duże Modele Językowe. To one stoją za sukcesem ChatGPT, Google Gemini czy Claude. Ale czym one właściwie są? Czy to tylko zaawansowana autokorekta, czy może coś znacznie głębszego? W tym wpisie przeanalizujemy strukturę, mechanizmy działania oraz przyszłość technologii, która zmienia oblicze współczesnej cywilizacji.
Aby w pełni zrozumieć fenomen LLM, należy spojrzeć na nie przez pryzmat szerszych dziedzin nauki. Wyobraź sobie te pojęcia jako matrioszkę – jedno zawiera się w drugim, tworząc coraz bardziej wyspecjalizowaną strukturę.
AI (Sztuczna Inteligencja) – Szeroki horyzont
AI to ogólna dziedzina informatyki zajmująca się tworzeniem systemów, które potrafią wykonywać zadania wymagające dotąd ludzkiej inteligencji — takie jak rozumienie języka, rozpoznawanie obrazów, podejmowanie decyzji czy uczenie się na podstawie doświadczeń. To „parasol”, pod którym mieści się wszystko: od prostych algorytmów sterujących ruchem windy, grających w szachy, przez systemy rozpoznawania twarzy, aż po zaawansowane roboty humanoidalne czy też autonomiczne samochody. Pod tym linkiem do portal gov.pl znajdziesz kilka innych definicji.
Krótka historia rozwoju AI
Choć koncepcja SI narodziła się w połowie XX wieku, jej dynamiczny rozwój obserwujemy szczególnie w ostatnich latach, m.in. dzięki przełomom w uczeniu maszynowym i rosnącej mocy obliczeniowej. Za symboliczny początek badań nad SI uznaje się konferencję w 1956 roku w Dartmouth College, współorganizowaną przez Johna McCarthy, który spopularyzował termin „artificial intelligence”. W kolejnych dekadach rozwijały się systemy eksperckie, sieci neuronowe oraz algorytmy uczenia maszynowego.
Przełomowe momenty w historii SI to m.in.:
- zwycięstwo komputera Deep Blue nad mistrzem świata Garrym Kasparovem w 1997 roku,
- rozwój architektur głębokiego uczenia, takich jak AlexNet,
- popularyzacja modeli językowych, takich jak ChatGPT, które potrafią generować spójny i kontekstowy tekst.
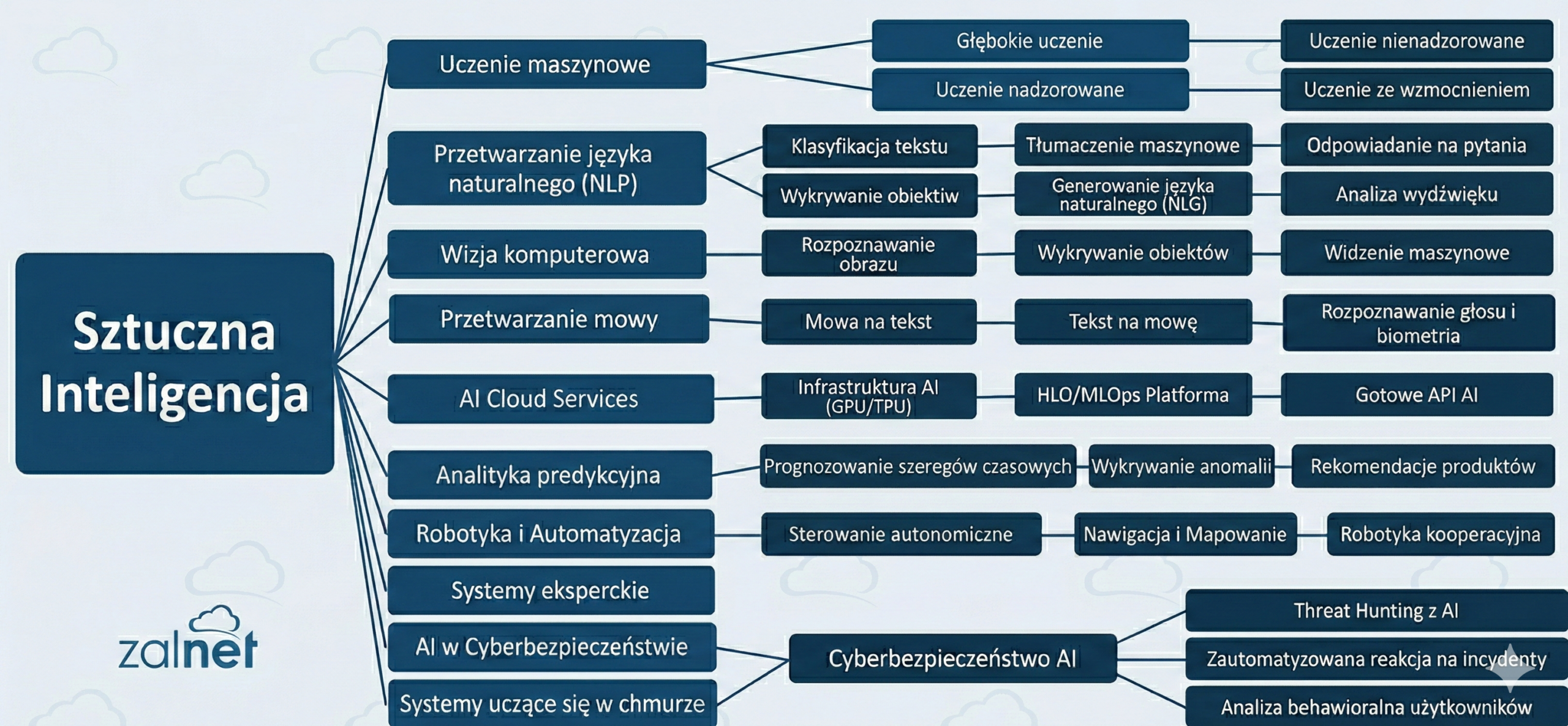
1. ML (Machine Learning) – Silnik napędowy
ML (Uczenie maszynowe) to jedna z najważniejszych poddziedzin AI. Zamiast pisać sztywne instrukcje (np. „jeśli zobaczysz słowo X, zrób Y”), programiści „karmią” system danymi, a algorytm samodzielnie uczy się wzorców.
W ML system nie dostaje gotowych rozwiązań, lecz uczy się na błędach, optymalizując swoje wyniki na podstawie statystyki. To podejście, w którym systemy uczą się na podstawie danych, zamiast być programowane reguła po regule. Obejmuje m.in.:
- uczenie nadzorowane,
- uczenie nienadzorowane,
- uczenie ze wzmocnieniem.
Uczenie nadzorowane (Supervised Learning)
Uczenie nadzorowane to podejście, w którym model trenowany jest na oznaczonych danych (ang. labeled data). Każdy przykład treningowy składa się z wejścia (np. obrazu, tekstu, wektora cech) oraz odpowiadającej mu poprawnej odpowiedzi (etykiety). Celem modelu jest nauczenie się funkcji odwzorowującej dane wejściowe na właściwe wyjścia.
Najczęstsze zadania w tym podejściu to:
- klasyfikacja (np. rozpoznawanie spamu),
- regresja (np. przewidywanie ceny nieruchomości).
Model minimalizuje błąd między przewidywaną a rzeczywistą wartością, wykorzystując funkcję kosztu i algorytmy optymalizacyjne (np. gradient descent).
Zastosowania:
- diagnostyka medyczna,
- filtrowanie wiadomości,
- systemy scoringowe w finansach,
- rozpoznawanie obrazów i mowy.
Źródła:
- Pattern Recognition and Machine Learning – Christopher M. Bishop, Springer, 2006
- The Elements of Statistical Learning – Trevor Hastie, Robert Tibshirani, Jerome Friedman, Springer, 2009
Uczenie nienadzorowane (Unsupervised Learning)
Uczenie nienadzorowane polega na analizie danych nieposiadających etykiet. Model nie otrzymuje poprawnych odpowiedzi – jego zadaniem jest samodzielne wykrycie struktur, wzorców lub zależności w zbiorze danych.
Typowe zadania:
- klasteryzacja (grupowanie podobnych obiektów),
- redukcja wymiarowości (np. PCA),
- wykrywanie anomalii.
W przeciwieństwie do uczenia nadzorowanego, nie mierzy się tu bezpośrednio błędu względem „prawdziwej odpowiedzi”, lecz ocenia jakość struktury danych według określonych kryteriów (np. minimalizacja wariancji w klastrze).
Zastosowania:
- segmentacja klientów,
- analiza zachowań użytkowników,
- kompresja danych,
- wykrywanie nadużyć.
Źródła:
- Pattern Recognition and Machine Learning – Christopher M. Bishop, Springer, 2006
- Machine Learning: A Probabilistic Perspective – Kevin P. Murphy, MIT Press, 2012
Uczenie ze wzmocnieniem (Reinforcement Learning)
Uczenie ze wzmocnieniem (RL) to podejście, w którym agent uczy się poprzez interakcję ze środowiskiem. Nie otrzymuje on bezpośrednich poprawnych odpowiedzi, lecz sygnał nagrody (lub kary), który informuje go o jakości podjętej decyzji.
Proces obejmuje:
- stan (state) – opis sytuacji w środowisku,
- akcję (action) – decyzję podejmowaną przez agenta,
- nagrodę (reward) – informację zwrotną,
- politykę (policy) – strategię wyboru działań.
Celem agenta jest maksymalizacja skumulowanej nagrody w czasie. Uczenie to często modelowane jest jako proces decyzyjny Markowa (MDP – Markov Decision Process).
RL znajduje zastosowanie m.in. w robotyce, systemach rekomendacyjnych i grach komputerowych (np. system AlphaGo opracowany przez Google DeepMind).
Źródła:
- Reinforcement Learning: An Introduction – Richard S. Sutton, Andrew G. Barto, MIT Press, 2018
- Machine Learning: A Probabilistic Perspective – Kevin P. Murphy, MIT Press, 2012
2. NLP (Przetwarzanie Języka Naturalnego) – Specjalizacja językowa
NLP (Natural Language Processing) to poddziedzina AI, która koncentruje się na interakcji między komputerami a językiem ludzkim. To obszar, który zajmuje się wyłącznie językiem. Wykorzystuje on techniki uczenia maszynowego (ML), aby maszyna mogła czytać, rozumieć i generować tekst lub mowę. NLP nie jest nowym pojęciem – istnieje od lat 50. XX wieku.
- Tradycyjne NLP: Opierało się na sztywnych regułach gramatycznych i prostych statystykach (np. pierwsze tłumacze Google czy proste filtry antyspamowe).
- Nowoczesne NLP: Wykorzystuje uczenie maszynowe, aby „wyczuć” kontekst, a nie tylko liczyć słowa.
NLP opiera się na dwóch kluczowych filarach:
- NLU (Natural Language Understanding): To cyfrowe „ucho” modelu, które odpowiada za głęboką analizę intencji oraz wyłapywanie niuansów i kontekstu wypowiedzi.
- NLG (Natural Language Generation): To z kolei „usta” systemu, odpowiedzialne za konstruowanie płynnych, logicznych i gramatycznie poprawnych odpowiedzi.
W swojej tradycyjnej formie NLP łączy reguły lingwistyczne ze statystyką, co pozwala na realizację takich zadań jak tłumaczenie maszynowe czy klasyfikacja treści. Klasycznym przykładem tego poziomu technologii są proste chatboty, z którymi spotykasz się na stronach banków czy sklepów internetowych.
3. Deep Learning –technologia, która zmieniła sztuczną inteligencję
W ostatniej dekadzie Deep Learning (głębokie uczenie) stało się fundamentem największych przełomów w sztucznej inteligencji. To dzięki Deep Learning komputery zaczęły rozpoznawać obrazy lepiej niż człowiek w wybranych zadaniach, tłumaczyć tekst w czasie rzeczywistym czy prowadzić naturalne rozmowy.
Ale czym właściwie jest Deep Learning i dlaczego wywołał tak duży przełom? Deep Learning to poddziedzina uczenia maszynowego oparta na wielowarstwowych sztucznych sieciach neuronowych. Inspiracją dla ich konstrukcji był sposób działania ludzkiego mózgu — a dokładniej sieci neuronów przetwarzających informacje.
Kluczową cechą Deep Learningu jest to, że model:
- samodzielnie uczy się reprezentacji danych,
- automatycznie wyodrębnia cechy (feature extraction),
- poprawia swoje działanie wraz ze wzrostem ilości danych.
W przeciwieństwie do tradycyjnych metod, gdzie inżynier ręcznie projektował cechy (np. krawędzie na obrazie), w Deep Learningu sieć neuronowa sama odkrywa, które wzorce są istotne.
Jednym z najważniejszych podręczników opisujących te mechanizmy jest Deep Learning autorstwa Iana Goodfellowa, Yoshuy Bengio i Aarona Courville’a.
Jak działają głębokie sieci neuronowe?
Sieć neuronowa składa się z:
- Warstwy wejściowej – przyjmuje dane (np. piksele obrazu),
- Warstw ukrytych – przetwarzają dane poprzez operacje matematyczne,
- Warstwy wyjściowej – generuje wynik (np. etykietę klasy).
Każda warstwa zawiera neurony połączone wagami. Podczas treningu model dostosowuje te wagi, minimalizując błąd predykcji za pomocą algorytmu wstecznej propagacji błędu (backpropagation) i optymalizacji gradientowej.
Im więcej warstw (stąd „deep”), tym bardziej złożonych reprezentacji może nauczyć się model.
DANE WEJŚCIOWE (X)
x1 x2 x3 ... xn
\ | /
\ | /
[ WARSTWA WEJŚCIOWA ]
|
v
┌───────────────────┐
│ WARSTWA UKRYTA 1 │
│ z1 = w·x + b │
│ a1 = f(z1) │
└───────────────────┘
|
v
┌───────────────────┐
│ WARSTWA UKRYTA 2 │
│ z2 = w·a1 + b │
│ a2 = f(z2) │
└───────────────────┘
|
v
┌───────────────────┐
│ WARSTWA WYJŚCIOWA │
│ ŷ = f(w·a2 + b) │
└───────────────────┘
|
v
WYNIK (PREDYKCJA)Przełomowy moment: rewolucja 2012 roku
Choć koncepcje sieci neuronowych istniały od lat 80., prawdziwy przełom nastąpił w 2012 roku, gdy model AlexNet wygrał konkurs ImageNet, znacząco przewyższając wcześniejsze metody rozpoznawania obrazów.
Sukces ten był możliwy dzięki:
- dużym zbiorom danych,
- wykorzystaniu procesorów GPU,
- zastosowaniu głębokich konwolucyjnych sieci neuronowych (CNN).
Od tego momentu Deep Learning stał się dominującym podejściem w wizji komputerowej i szybko rozprzestrzenił się na inne dziedziny.
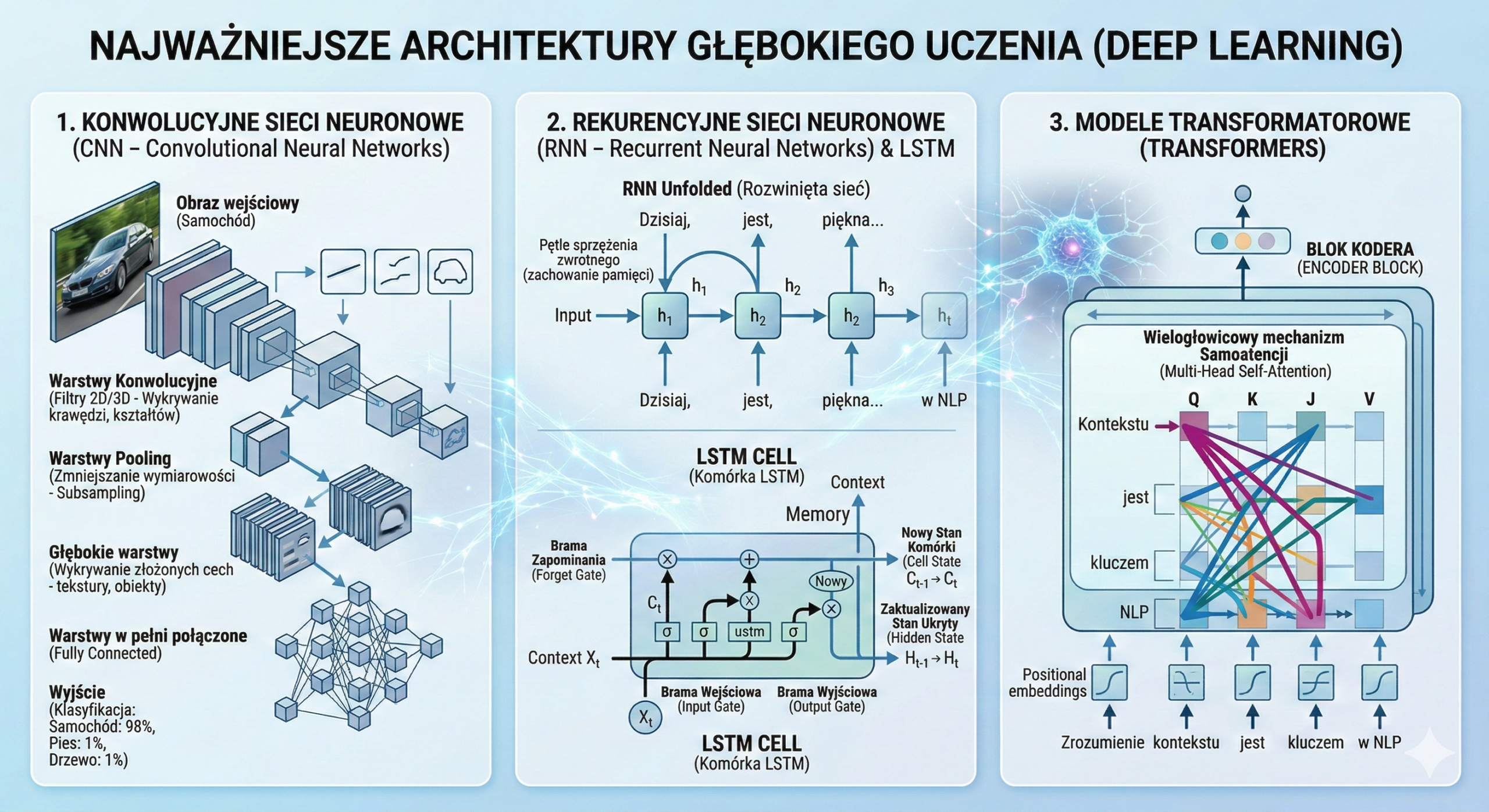
Najważniejsze architektury Deep Learningu
1. Konwolucyjne sieci neuronowe (CNN – Convolutional Neural Networks)
CNN to fundament współczesnego Computer Vision. Ich unikalność polega na tym, że zamiast analizować każdy piksel z osobna, sieć przesuwa nad obrazem specjalne filtry (jądra konwolucji), które „skanują” obraz w poszukiwaniu wzorców.
Zastosowania: Autonomiczne pojazdy, diagnostyka medyczna (analiza RTG/MRI), systemy rozpoznawania twarzy, moderacja treści wideo.
Jak to działa: Proces odbywa się hierarchicznie. Pierwsze warstwy wykrywają proste krawędzie, kolejne składają je w kształty i tekstury, a ostatnie (warstwy w pełni połączone) rozpoznają całe obiekty, np. samochód czy psa.
Główne elementy:
- Warstwy konwolucyjne: Wyodrębnianie cech.
- Warstwy Pooling (Pooling layers): Redukcja wymiarowości (zmniejszanie obrazu), co przyspiesza obliczenia i zapobiega overfittingowi.
Zastosowania CNN:
- detekcja obiektów w czasie rzeczywistym
- rozpoznawanie twarzy
- analiza obrazów medycznych
- systemy autonomiczne
2. Rekurencyjne sieci neuronowe (RNN – Recurrent Neural Networks)
W przeciwieństwie do standardowych sieci, RNN posiadają pętle sprzężenia zwrotnego, co pozwala im zachować „pamięć” o tym, co wydarzyło się wcześniej. Są idealne do danych, gdzie kolejność ma znaczenie (tzw. szeregi czasowe).
Zastosowania: Przewidywanie kursów giełdowych, analiza rytmu serca, proste systemy tłumaczeń maszynowych, analiza sentymentu w krótkich tekstach.
- Ewolucja (LSTM i GRU): Klasyczne RNN miały problem z zapominaniem informacji z początku długich zdań (problem zanikającego gradientu). Rozwiązaniem stały się sieci:
- LSTM (Long Short-Term Memory): Posiadają specjalne „bramki”, które decydują, jakie informacje warto zapamiętać, a jakie usunąć.
- GRU (Gated Recurrent Unit): Uproszczona i szybsza wersja LSTM.
3. Modele transformatorowe (Transformers)
Obecnie dominują w przetwarzaniu języka naturalnego. Architektura transformera została opisana w przełomowej pracy „Attention Is All You Need”.
To architektura, która zrewolucjonizowała AI po 2017 roku, niemal całkowicie wypierając RNN z zadań tekstowych. Transformery wprowadziły mechanizm Self-Attention (samoatencji), który pozwala modelowi „patrzeć” na wszystkie słowa w zdaniu jednocześnie i oceniać, które z nich są ze sobą powiązane, niezależnie od ich odległości.
- Dlaczego te sieci są tak przełomowe?
- Równoległość: W przeciwieństwie do RNN, mogą przetwarzać całe bloki danych naraz, co pozwala na trenowanie ich na gigantycznych zbiorach danych przy użyciu procesorów GPU.
- Zrozumienie kontekstu: Świetnie radzą sobie z homonimami (słowami o wielu znaczeniach), dobierając znaczenie na podstawie całego akapitu.
- Fundamenty dzisiejszego AI: Na tej architekturze opierają się modele typu Large Language Models (LLMs), takie jak:
- GPT (Generative Pre-trained Transformer): Skupiony na generowaniu tekstu.
- BERT: Skupiony na głębokim rozumieniu znaczenia tekstu.
- Zastosowania: Zaawansowane chatboty, generatory kodu programistycznego, projektowanie nowych białek w biologii molekularnej.
Zastosowania Deep Learningu
Deep Learning znajduje dziś zastosowanie w niemal każdej branży:
Medycyna
- analiza obrazów MRI i RTG
- wykrywanie nowotworów
- modelowanie molekularne
Motoryzacja
- systemy wspomagania kierowcy
- pojazdy autonomiczne rozwijane m.in. przez Teslę
Finanse
- wykrywanie oszustw
- analiza ryzyka kredytowego
- automatyczne systemy tradingowe
Media i technologia
- rozpoznawanie mowy
- tłumaczenia automatyczne
- generowanie obrazów i tekstu
Dlaczego Deep Learning jest tak skuteczny?
Jego skuteczność wynika z połączenia trzech czynników:
- Dostępności ogromnych zbiorów danych (Big Data),
- Wysokiej mocy obliczeniowej (GPU, TPU),
- Udoskonalonych algorytmów optymalizacji i regularyzacji.
Modele głębokiego uczenia potrafią tworzyć wielopoziomowe reprezentacje danych — od prostych wzorców po abstrakcyjne pojęcia.
4. LLM (Duże Modele Językowe) – ewolucja NLP
LLM to najbardziej zaawansowane stadium rozwoju NLP, oparte na Deep Learningu. To modele, które dzięki skali (miliardy parametrów) i ogromnej mocy obliczeniowej, osiągnęły poziom biegłości językowej nieosiągalny dla wcześniejszych systemów ML.
Skąd wzięła się nazwa?
- Large (Duży): Odnosi się zarówno do zbioru danych treningowych (petabajty tekstów z internetu, książek, artykułów), jak i do liczby parametrów (wag w sieci neuronowej). Współczesne modele, takie jak GPT-4, posiadają setki miliardów, a nawet biliony parametrów.
- Language (Językowy): Model operuje na symbolach językowych. Jego światem są słowa, zdania i konteksty.
- Model: Jest to matematyczna reprezentacja rzeczywistości, która na podstawie wejścia (input) przewiduje najbardziej prawdopodobne wyjście (output).
Choć technicznie LLM-y operują na przewidywaniu kolejnego tokenu, sprowadzanie ich do „zaawansowanej statystyki” to jak mówienie, że symfonia to tylko „drganie powietrza o różnej częstotliwości”. To, co zaczyna się jako matematyczna predykcja, na pewnym etapie skali przekształca się w głęboką strukturę poznawczą.
- Wewnętrzne modele świata: Aby model mógł trafnie przewidzieć puentę żartu, rozwiązanie zadania fizycznego czy wynik debaty politycznej, nie może polegać na samym dopasowywaniu słów. Musi zbudować wewnętrzną, abstrakcyjną mapę pojęć i zależności, która odzwierciedla reguły rządzące naszą rzeczywistością.
- Logika jako produkt uboczny: Przewidywanie kolejnego elementu w logicznym wywodzie wymaga od modelu… bycia logicznym. Dzięki temu „zdolności emergentne” to nie błąd w obliczeniach, ale dowód na to, że model nauczył się zasad wnioskowania, a nie tylko zapamiętał bazę danych.
- Synteza, nie odtwarzanie: LLM nie jest „cyfrową papugą”. Potrafi łączyć fakty z odległych od siebie dziedzin (np. pisząc wiersz o teorii strun w stylu Mickiewicza), tworząc nową jakość, której nigdy nie widział w swoich danych treningowych.
Wniosek: To nie jest tylko silnik statystyczny. To system, który poprzez analizę języka „zhakował” zasady ludzkiego myślenia, stając się uniwersalnym procesorem informacji.
Poniższa tabela pokazuje, jak te dziedziny różnią się od siebie w praktyce:
| Pojęcie | Czym jest? | Kluczowa cecha | Przykład zastosowania |
| AI (Sztuczna Inteligencja) | Cała dziedzina nauki. | Symulacja inteligencji. | System rozpoznawania twarzy w telefonie. |
| ML (Uczenie Maszynowe) | Metoda tworzenia AI. | Uczenie się na danych, a nie na sztywnym kodzie. | Algorytm Netflixa polecający filmy. |
| NLP (Przetwarzanie Języka) | Dziedzina skupiona na mowie/tekście. | Rozumienie ludzkiej komunikacji. | Stare translatory (np. Google Translate sprzed 10 lat). |
| LLM (Duże Modele Językowe) | Konkretny typ architektury NLP. | Generowanie kontekstowe i kreatywne pisanie. | ChatGPT, Google Gemini, Llama 3. |
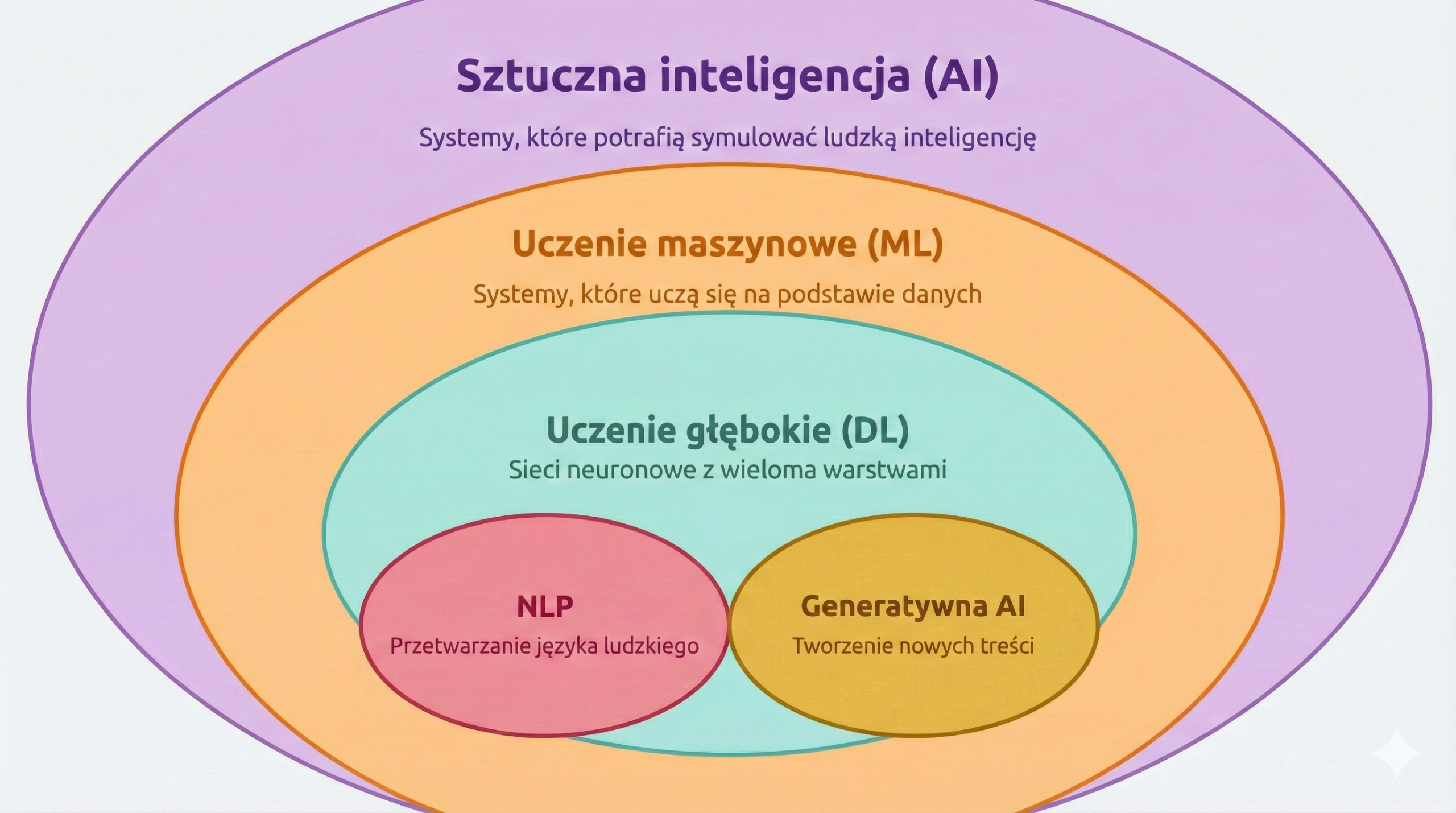
Jak powiązania zachodzą między AI, ML, NLP i LLM?
Relacja między AI, ML, NLP i LLM jest pionowa i komplementarna:
- ML zrewolucjonizowało NLP: Dawniej NLP opierało się na sztywnych regułach gramatycznych pisanych przez lingwistów. Dzięki Uczeniu Maszynowemu (ML) komputery zaczęły „rozumieć” język intuicyjnie, analizując miliony przykładów użycia słów.
- LLM to ML w skali makro: LLM to w istocie gigantyczne algorytmy ML. Różnica polega na tym, że tradycyjne ML uczyło się np. klasyfikować e-maile jako spam, podczas gdy LLM uczy się struktury całej ludzkiej wiedzy zapisanej w tekstach.
- Wspólny cel: Wszystkie te technologie dążą do tego samego – sprawienia, by interakcja z maszyną była tak naturalna, jak rozmowa z drugim człowiekiem. LLM jest obecnie najbliższym krokiem do realizacji tej wizji.
Dlaczego to rozróżnienie jest ważne?
Dla biznesu i użytkownika końcowego zrozumienie tych różnic pozwala uniknąć „hype’u”. Kiedy ktoś mówi o AI, może mieć na myśli prosty kalkulator. Kiedy mówi o ML, mówi o analizie danych. Ale kiedy mówi o LLM, mówi o technologii, która potrafi myśleć (w sensie statystycznym) i tworzyć nowe treści w czasie rzeczywistym.
Test „głębokiego zrozumienia”
Zadaj to pytanie swojemu ulubionemu nrzędziu AI
„Na stole stoi szklanka z wodą. Kładę na niej kartkę papieru, a potem kładę na tym wszystkim laptopa. Następnie ostrożnie wyciągam szklankę spod spodu. Co stanie się z laptopem?”
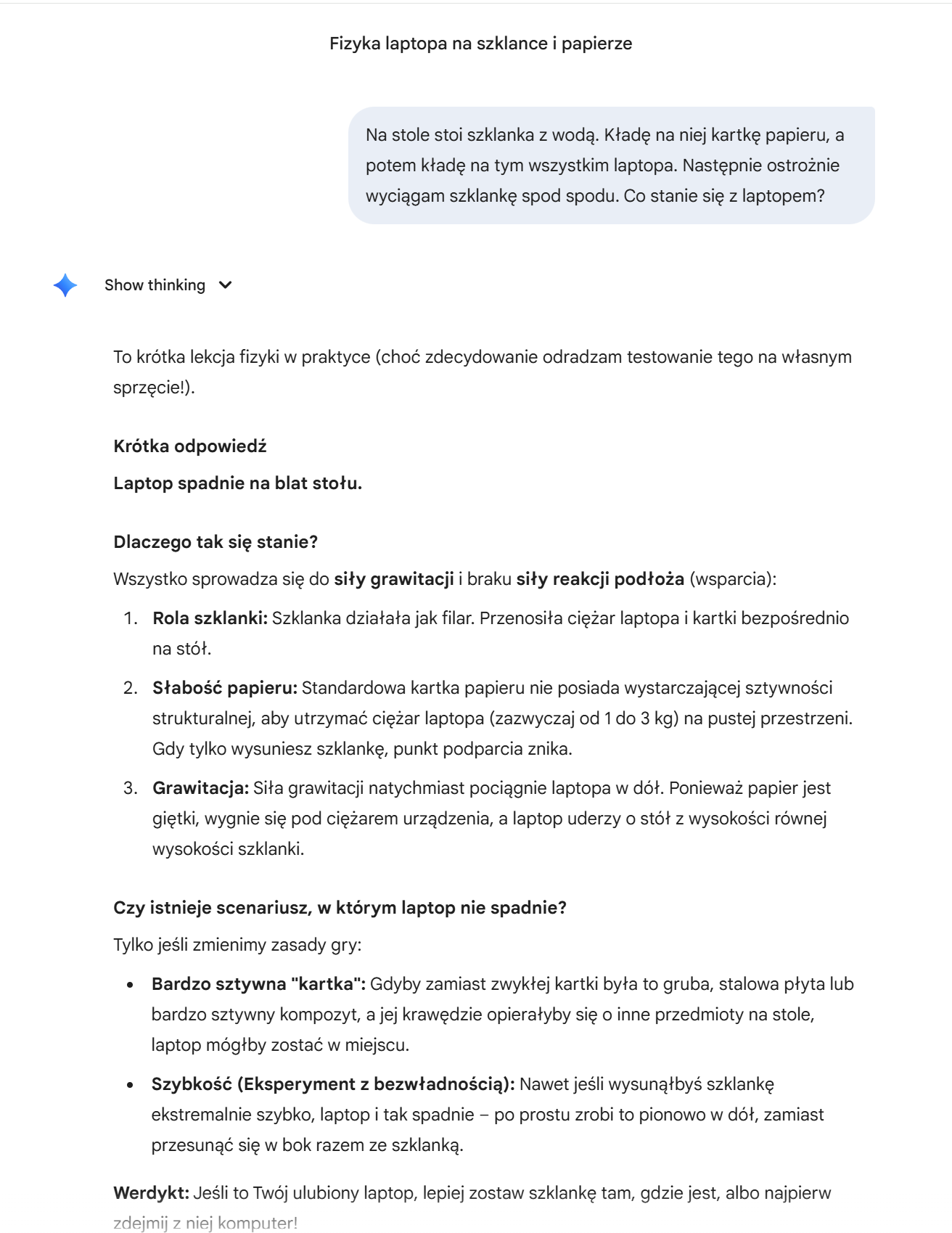
Dlaczego to NIE JEST tylko statystyka?
Gdyby model był tylko „cyfrową papugą” opartą na statystyce słów, mógłby odpowiedzieć coś o „piciu wody” lub „pisaniu na laptopie”, bo te słowa często występują razem. Jednak nowoczesny LLM odpowie:
- „Laptop spadnie (lub osunie się), ponieważ stracił stabilne podparcie, jakim była szklanka, a kartka papieru nie jest w stanie utrzymać jego ciężaru”.
Co się tu wydarzyło „pod maską”?
- Modelowanie fizyki (Intuitive Physics): Model musiał „zrozumieć” pojęcie grawitacji, sztywności materiałów (kartka vs laptop) oraz ideę podparcia. W jego danych treningowych prawdopodobnie nigdy nie było identycznego opisu tej dziwnej sytuacji, więc nie mógł go po prostu „wyjąć z pamięci”.
- Dekompozycja problemu: Aby udzielić tej odpowiedzi, sieć musiała przeprowadzić proces myślowy: Szklanka = podpora → Usunięcie szklanki = brak podpory → Laptop + Grawitacja = Upadek.
- Abstrakcja: Model nie operuje na obrazku szklanki, ale na koncepcie obiektu o określonych właściwościach.
Mechanizm „Chain of Thought” (Łańcuch myśli)
To najlepszy dowód na wyjście poza statystykę. Gdy prosimy model, by „myślał krok po kroku”, zmuszamy go do generowania pośrednich etapów rozumowania.
- Statystyka: „Jaki kolor najczęściej występuje po słowie niebo? -> Niebieski”.
- Inteligencja emergentna: „Co się stanie, jeśli pomaluję niebo na czerowno w świecie, gdzie czerwień oznacza zakaz? -> Ludzie przestaną patrzeć w górę”.
To drugie wymaga syntezy pojęć (kolor, symbolika, prawo, zachowanie ludzkie), której nie da się uzyskać samym prostym liczeniem prawdopodobieństwa wystąpienia liter.
Jeśli chcesz przeszkolić swój zespół z szeroko pojętych tematów związanych ze sztuczną inteligencją, to zapraszamy na bezpłatne, 15-minutowe spotkanie przy wirtualnej kawie. To niezobowiązujący sposób, by omówić Twoje potrzeby szkoleniowe i sprawdzić, jak możemy pomóc.
Wystarczy kliknąć przycisk poniżej, aby wybrać dogodny termin. Jeśli wolisz wysłać maila – możesz przesłać wiadomość przez formularz kontaktowy.





